基本数据类型
数据类型长度是固定的,与操作系统无关。
没有任何
unsigned类型,也就是都包含负数。强烈建议在使用
long和float类型时,显式声明后缀(并且是大写的后缀:L、D)。因为:
没有后缀的浮点数,例如:3.14,默认为double类型。
没有后缀的整数,例如:1024,默认为int类型。
不要直接使用浮点数进行运算。可以考虑将其转换成整型再进行计算。
当你执行
System.out.println(1.3-1.2)时,你会惊奇的发现,结果不是 0.1 也不是 0.10000000000000000,而是 0.10000000000000009 (或者是其他相近的字符串,例如:0.09999999999999987)!
这是因为二进制无法精确的表示 1/10 ,就像十进制也没办法精确表示 1/3 一样。如果需要精确运算,可以使用
java.math.BigInteger和java.math.BigDecimal。Java 为了保证浮点数算术运算的可移植性,最初规定了浮点数的中间计算都会进行截断。
例如:
计算double r = x * y / z时,会先计算x * y,得到的结果截断成 64 位,然后再除以z。
这样的方式显然会丢失一部分精度,但是可以保证运算结果的可移植性。但是,为了使计算结果更加精确,现在的虚拟机默认允许,中间计算结果采用扩展精度。
也就是说,如果你的 CPU 使用 80 浮点数寄存器,那么x * y的结果会存储到 80 位,然后再进行计算。
这样会得到一个更精确的结果,但是在不同的硬件平台上,同样的代码所执行的结果可能会不一致。strictfp这个关键字(目前我还没有没有使用过),它可以用来修饰类、接口或者是方法,强制要求虚拟机使用严格的浮点数计算方法(也就是第一种方法)。对于二元运算符,会先把两边的变量,转换成相同类型(转换的顺序为:
double-float-long-int),再做运算。因此,保证参与运算的数值类型一致,可以避免很多莫名其妙的错误。
范围小的基本类型转换为范围大的基本类型,编译器会自动加宽。
对于可能丢失精度的合法转换,请慎重使用!
如需强制转换,务必考虑结果是否会溢出,否则结果将不可预料。
例如:(byte) 128 == (byte) -128!不同类型的存储要求和取值范围:
整型取值公式:-2n-1 ~ 2n-1 - 1(n 是存储位数,n-1,减的就是符号位)
浮点型取值公式:比较复杂,可以查阅 IEEE 754 浮点数算术标准
| 类型 | 存储位数(n) | 取值范围 | 缺省值 |
|---|---|---|---|
| byte | 8 bit = 1 byte | -128 ~ 127 | 0 |
| short | 16 bit = 2 byte | -32,768 ~ 32,767 | 0 |
| int | 32 bit = 4 byte | -2,147,483,648 ~ 2,147,483,647 (约21亿) | 0 |
| long | 64 bit = 8 byte | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 0L |
| float | 32 bit = 4 byte | 2-149 ~ (2-2-23)*2127(精度6-7位) | 0.0F |
| double | 64 bit = 8 byte | 2-1074 ~ (2-2-52)*21023(精度15-16位) | 0.0D |
| char | 16 bit = 2 byte | \u0000’ ~ ‘\uffff’ (0-65,535) | \u0000’ |
| boolean | 1 bit | false,true | false |
数据类型之间的转换关系: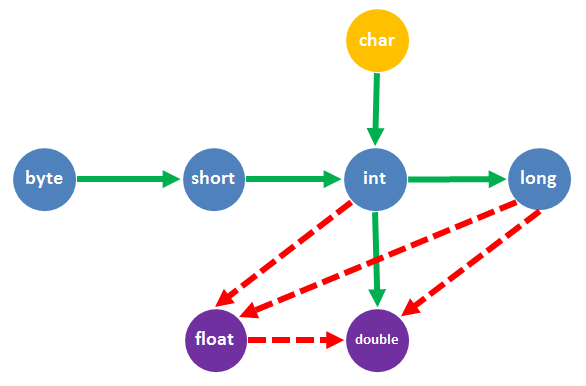
在实际工作中我很少使用
short、float、char类型。尽量不要使用非十进制表示方法,因为不够直观:
| 进制 | 前缀 | 实例 | 十进制值 |
|---|---|---|---|
| 二进制(JDK 1.7 后才有) | 0b | 0b10 | 2 |
| 八进制 | 0 | 010 | 8 |
| 十六进制 | 0x | 0x10 | 16 |
JDK 1.7 以后还可以使用下划线分隔数字,暂时还没用到
例如:
100_100_100 = 100100100
包装类
首先,包装类是 final 类, 不可继承:
1 | public final class Integer extends Number implements Comparable<Integer> |
其次,一旦构造了包装器,就不允许改变它的值:
1 | private final int value; |
在基本类型和包装类相互转换时,实际上是使用了包装类的构造方法和
xxxValue()方法。所谓的: Auto-Boxing 和 UnBoxing(自动装箱,拆箱 ),也就是编译器在背后默默地帮你做了这些事情。
例如:装箱,
int自动转换为Integer:1
Integer integer = 1024;
相当于:
1
Integer integer = new Integer(1024);
关于自动装箱,还有一个地方需要注意的:基本类型可以先加宽,然后转为宽类型的包装类,但是不能直接转换。
拆箱,
Integer自动转换为int:1
int i = integer;
相当于:
1
int i = integer.intValue();
利用包装类还可以实现字符串和基本类型的转换。
例如:
int 转换为 String:String s = String.valueOf(1024);
String 转换为 int:int i = Integer.parseInt(s);说到这里,或许你会想,
int转换为String,直接这样不是更简单:1
String s = "" + 1024;
实际上,如果你知道
String是怎么重载+运算符的话,你就不会这么用了。
上面的代码,相当于:1
2
3
4StringBuilder bulider = new StringBuilder();
bulider.append(String.valueOf(""));
bulider.append(String.valueOf(1024));
String s = bulider.toString();包装类的对象和其他所有类的对象一样,缺省值也是 null 。
在
==面前也是类类平等。
不要轻易尝试去趟integerA == integerB这样的坑。
因为,不同包装类的valueOf()方法实现也是很不一样的,有兴趣的同学,可以翻它们的源代码看看。
总的来说,很多地方我们不可避免的需要使用到包装类。
例如:在集合中。
但是,如果我们滥用包装类,由于存在自动拆装箱的机制,还有可能会产生一些性能问题。
因此,我的原则是:能不用包装类,就不用。
大数值
前面已经提到浮点数的精度问题,一般在商业计算中,会要求使用 BigDecimal 来保证精度。BigDecimal 的 API 很简单。加减乘除都封装好了,不难理解。
舍入模式
看看下面的表格保证你就清楚了。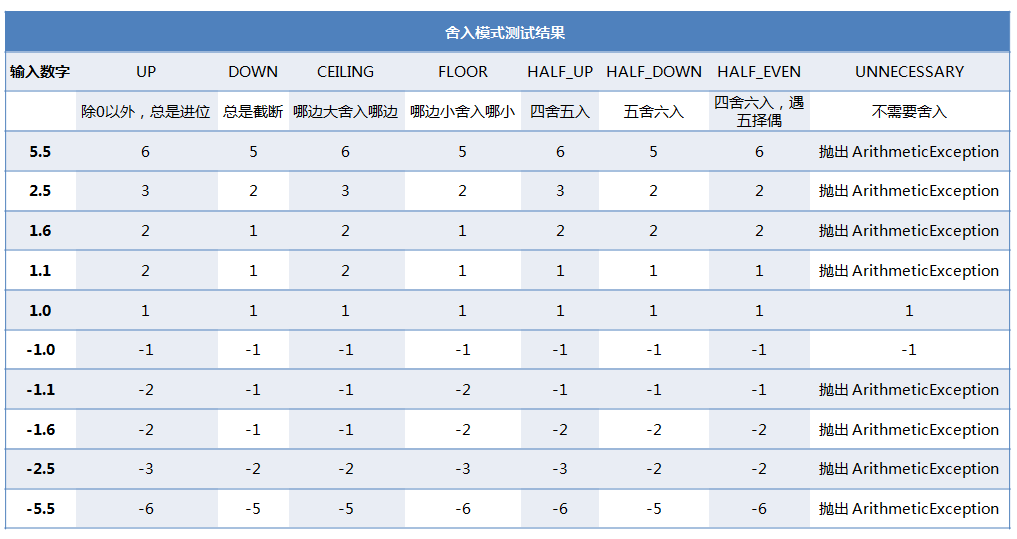
银行家舍入法的口诀是,“四舍六入,遇五择偶”。
其要点是:遇到 5 的时候总是向最接近于它的偶数舍入。
如果需要进行一系列的舍入操作,这种方式可以减少累积的偏差。

